













这两年AI技术全面渗透到各行各业,音频领域更是迎来革新,声音克隆工具成为音乐创作、短视频配音的刚需神器,市面上工具五花八门,今天给大家安利一款小米自研的,实测效果拉满!

OmniVoice是什么
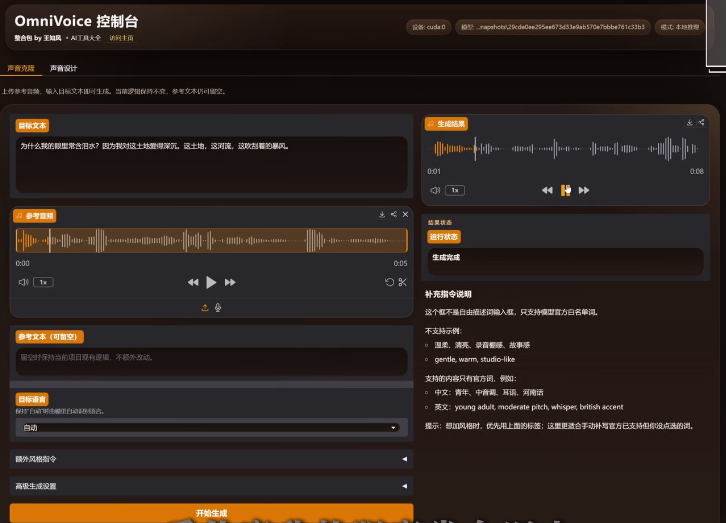
OmniVoice是一款先进的大规模多语言零样本文本转语音(TTS)模型,支持600多种语言。它基于一种新颖的扩散语言模型架构,能够生成高质量的语音,具有卓越的推理速度,并支持语音克隆和语音设计。
OmniVoice主要特点
支持600多种语言:零样本TTS模型中最广泛的语言覆盖范围(完整列表)。
语音克隆:最先进的语音克隆质量。
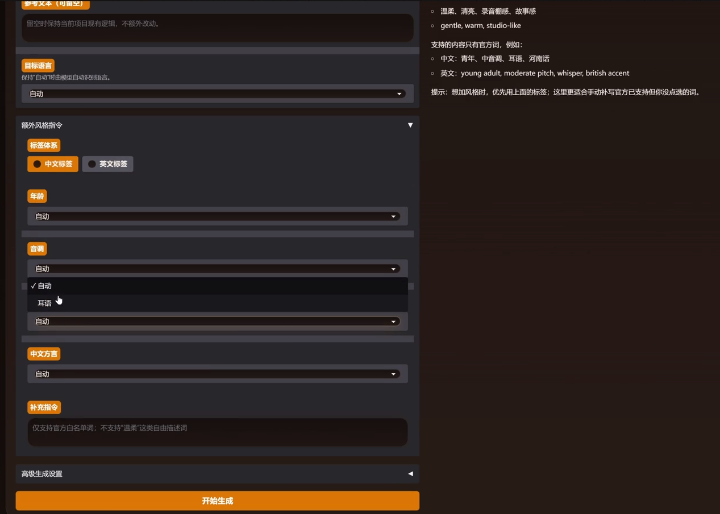
语音设计:通过指定的说话人属性(性别、年龄、音调、方言/口音、耳语等)控制语音。
精细控制:非语言符号(例如,[laughter])和通过拼音或音素进行发音纠正。
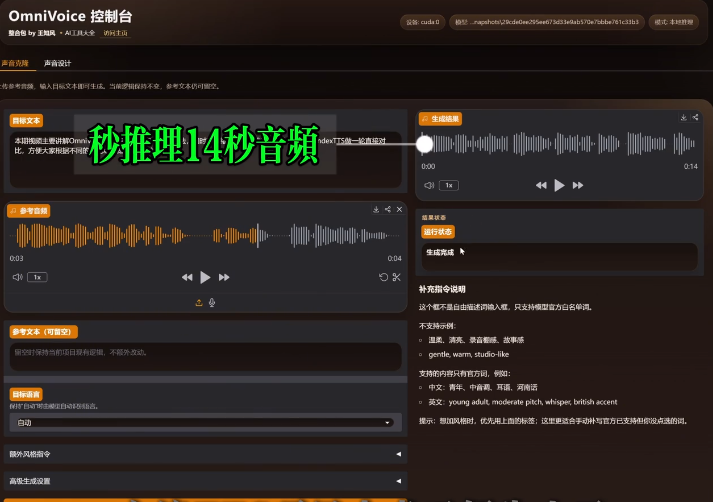
快速推理:RTF低至0.025(比实时快40倍)。
扩散语言模型风格的架构:一种简洁、精简且可扩展的设计,兼顾质量和速度。
如何使用OmniVoice
安装部署:用户可通过pip命令或从GitHub克隆源码,执行安装命令完成OmniVoice的部署。
快速体验:用户无需编写代码可通过启动本地Web服务或访问HuggingFace在线Demo来快速体验OmniVoice的语音合成效果。
语音克隆:开发者可用PythonAPI加载预训练模型,通过提供参考音频和转写文本实现零样本语音克隆功能。
音色设计:用户可通过自然语言描述说话人的性别、年龄、音调、口音等属性来直接设计生成特定的音色。
命令行工具:系统支持通过命令行工具进行单条语音合成或跨多GPU的批量推理任务处理。
细粒度控制:用户可在合成文本中插入特定标签来添加笑声、叹气等副语言表达,或使用拼音和音素符号纠正多音字及专有名词的发音。
OmniVoice的关键信息和使用要求
技术定位:OmniVoice是小米AI实验室开源的基于扩散语言模型的非自回归TTS系统,采用极简双向Transformer架构直接映射文本至多码本声学token,摒弃传统级联pipeline,支持600+语种的零样本语音克隆与合成。
核心参数:模型拥有0.8B参数并基于Qwen3-0.6B初始化,基于58.1万小时开源语音数据训练覆盖646个语种,推理速度达RTF0.025(40倍实时),在中英文及多语言基准测试中的说话人相似度与可懂度指标均达到SOTA水平。
功能边界:支持3-10秒参考音频的零样本语音克隆(含带噪/混响音频去噪)、基于性别/年龄/音调/方言/口音等属性的音色设计、以及通过标签和拼音/音素实现的副语言控制与发音纠正。
硬件环境:需要支持CUDA的NVIDIAGPU(推荐H800/H20以发挥最佳性能)或支持MPS的AppleSilicon设备来运行模型推理。
软件依赖:需在Python虚拟环境中安装PyTorch(匹配CUDA版本)并通过pip或源码安装omnivoice包满足运行依赖。
OmniVoice的核心优势
架构极简高效:采用单阶段非自回归扩散语言模型架构,用一个双向Transformer直接映射文本至多码本声学token,消除传统级联pipeline的误差传播与信息瓶颈,实现架构简洁性与性能的双重突破。
语言覆盖最广:基于58.1万小时开源数据训练,支持600+语种的零样本语音合成,在低资源小语种上仍保持极低字错误率,是目前语言覆盖范围最广的TTS模型。
推理速度极快:通过全码本随机masking策略与高效架构设计,实现RTF低至0.025的推理速度,即40倍快于实时,显著优于自回归模型。
音质与可懂度SOTA:借助LLM初始化继承预训练语言知识,在LibriSpeech-PC、Seed-TTS等基准测试中,说话人相似度(SIM-o)与可懂度(WER)均超越现有非自回归模型及商用系统。
多维可控能力:支持零样本语音克隆、基于属性的音色设计、带噪音频去噪、副语言符号(笑声/叹气)插入及拼音/音素级发音纠正,满足复杂场景下的细粒度控制需求。
更新日志
发生了哪些变化?
修复:infer_batch中的指令@Pastells在第72号
文档:通过以下方式将omnivoice-server添加到社区项目@maemreyo第42号
修复:缺少ref_text或ref_audio_path参数的batch_inference@Pastells第70号
文档:恢复omnivoice-server对社区项目的支持(强制推送后)@maemreyo第80号
修复infer_batch.py以支持混合模式58cf379
请使用soundfile+librosa代替torchaudio以避免某些设备上出现问题4f4b0cc
将文本31b8a4d中的中文括号替换为英文括号。
在README8ede7ac中添加更多提示
添加GoogleColab示例9361466
- PC官方版
- 安卓官方手机版
- IOS官方手机版
 novamss音源分离软件(人声分离)1.4.0 社区版
novamss音源分离软件(人声分离)1.4.0 社区版
 祈风TTS配音软件v0.1.3.2 最新版
祈风TTS配音软件v0.1.3.2 最新版
 心月AI变声器5.0.exe5.0 电脑版
心月AI变声器5.0.exe5.0 电脑版
 AIMP音频转换器5.03.2394 便携版
AIMP音频转换器5.03.2394 便携版
 Switch Plus by NCH Softwara(音频转换工具)7.45绿色中文版
Switch Plus by NCH Softwara(音频转换工具)7.45绿色中文版
 Easy M4P Converter(M4P转MP3工具)6.6.6官方版
Easy M4P Converter(M4P转MP3工具)6.6.6官方版
 QQ语音一键转发工具1.0.7 中文免费版
QQ语音一键转发工具1.0.7 中文免费版
 音频设备切换工具(SoundSwitch )4.11 简体中文版
音频设备切换工具(SoundSwitch )4.11 简体中文版
 音频音量放大软件(Audio Amplifier Pro)2.2.0 免费版
音频音量放大软件(Audio Amplifier Pro)2.2.0 免费版
 海海音频音效工具5.3官方版
海海音频音效工具5.3官方版
 简谱转调工具v1.1 最新免费版
简谱转调工具v1.1 最新免费版
 简谱转调软件(Jianpu Easy Trans)1.0 绿色版
简谱转调软件(Jianpu Easy Trans)1.0 绿色版
 Leawo Prof Media(视频转换器)7.9 中文破解版
Leawo Prof Media(视频转换器)7.9 中文破解版
 酷特简谱作曲家软件9.05官方正式版
酷特简谱作曲家软件9.05官方正式版
 人声变音效果器Polyverse Infected Mushroom Manipulator1.0.3.CE-VR
人声变音效果器Polyverse Infected Mushroom Manipulator1.0.3.CE-VR
 英语单词语音生成器2.0免费版
英语单词语音生成器2.0免费版
 最全70款语音包合集最新完整版
最全70款语音包合集最新完整版
 吃鸡语音设置工具(Soundpad)3.4.10 官方版
吃鸡语音设置工具(Soundpad)3.4.10 官方版
 李云龙表白田雨语音包MP3免费版
李云龙表白田雨语音包MP3免费版
 果子哥哥吃鸡语音包完整搞笑版
果子哥哥吃鸡语音包完整搞笑版
 吃鸡语音包合集工具1.3 绿色免费版
吃鸡语音包合集工具1.3 绿色免费版
 音乐迷(无损音乐下载器)pc版1.0绿色版
音乐迷(无损音乐下载器)pc版1.0绿色版
 音频转换专家最新版9.3 免费版
音频转换专家最新版9.3 免费版
 Program4Pc音频转换器6.0 破解版
Program4Pc音频转换器6.0 破解版
 枫叶音频格式转换器7.8.3.0 最新版
枫叶音频格式转换器7.8.3.0 最新版
 QVE音频转换器1.0.24 最新版
QVE音频转换器1.0.24 最新版
 迅捷音频转换器1.0.0 最新版
迅捷音频转换器1.0.0 最新版
 闪电音频格式转换器3.2.3.0 官方版
闪电音频格式转换器3.2.3.0 官方版
 Eufony免费M4A MP3转换器v1.2 免费版
Eufony免费M4A MP3转换器v1.2 免费版
 森然音效转换软件v1.0.0.1 官方版
森然音效转换软件v1.0.0.1 官方版





 免费音频转换器(VSDC Free Audio Converter
免费音频转换器(VSDC Free Audio Converter 安可音频转换工具1.1 绿色免费版
安可音频转换工具1.1 绿色免费版 随心音乐台(单文件)1.8 绿色免费版【去广告
随心音乐台(单文件)1.8 绿色免费版【去广告 Sound Radix POWAIR1.1 免费版
Sound Radix POWAIR1.1 免费版 九腾免费3gp格式转换器1.1 绿色免费版
九腾免费3gp格式转换器1.1 绿色免费版 王超音效外置声卡电音8.6.0.0 绿色免费版
王超音效外置声卡电音8.6.0.0 绿色免费版 野狼电音精灵6.6 官方正式版
野狼电音精灵6.6 官方正式版